|
Liwei Wang
I am an Assistant Professor in Computer Science and Engineering department at The Chinese University of Hong Kong (CUHK). Before coming to HK, I have worked for more than two years as a Senior Researcher in Tencent America at Bellevue, US. Email / Google Scholar / Publications / Lab website (soon) / |

|
News
|
|
Recent Research Highlights
My students / interns / postdocs are indicated by '*'. Click full publication list |
|
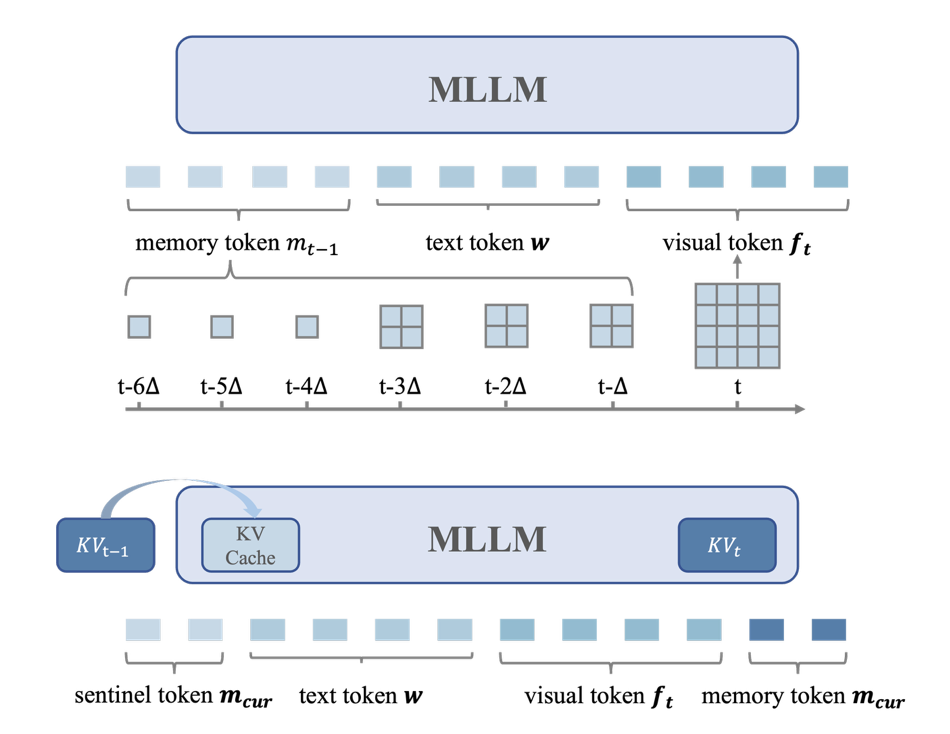
Efficient-VLN: A Training-Efficient Vision-Language Navigation Model Arxiv 2025 Project |
|
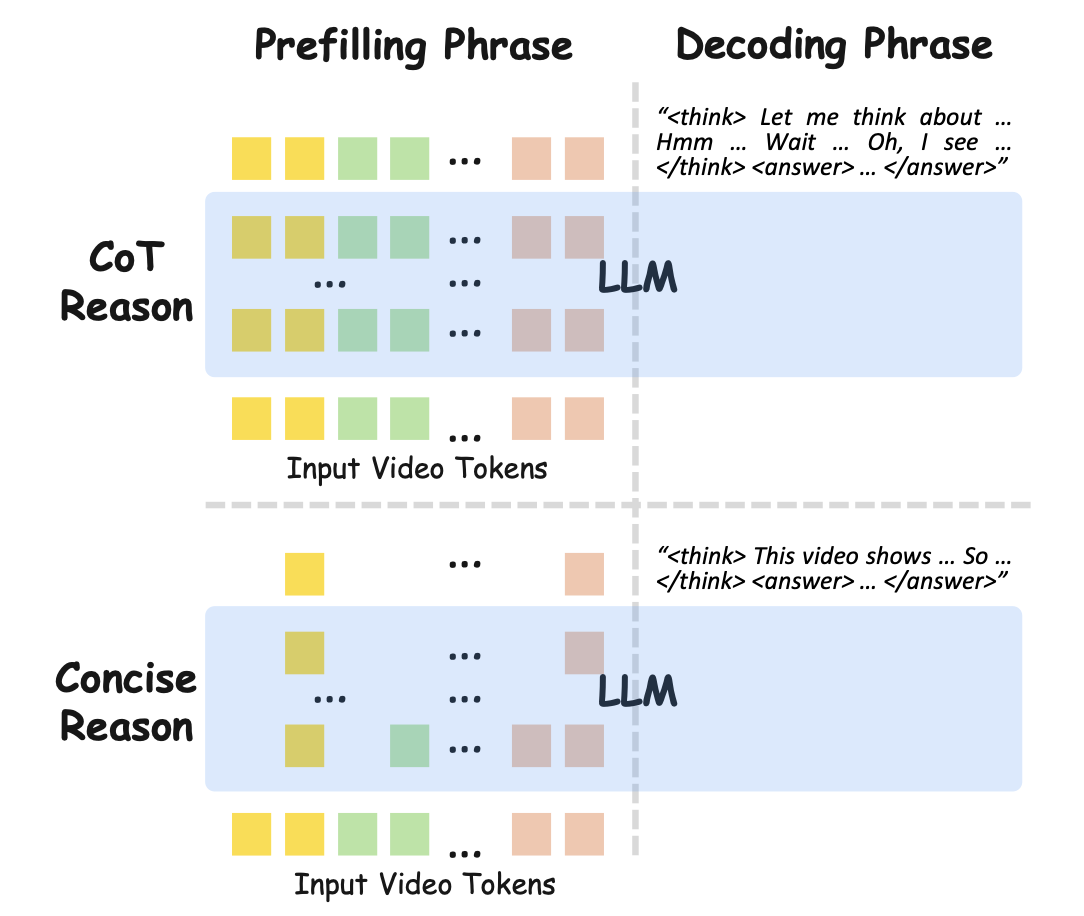
Rethinking Chain-of-Thought Reasoning for Videos Arxiv 2025 Code soon |
|
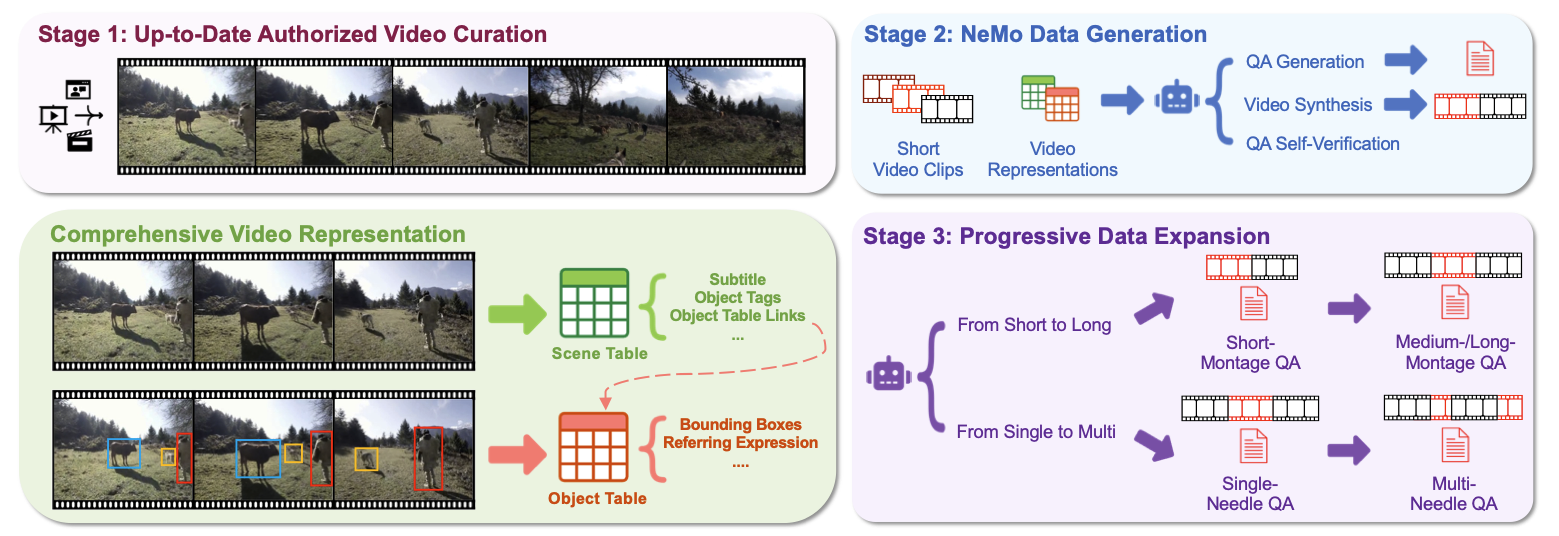
NeMo: Needle in a Montage for Video-Language Understanding Arxiv 2025 Project |
|
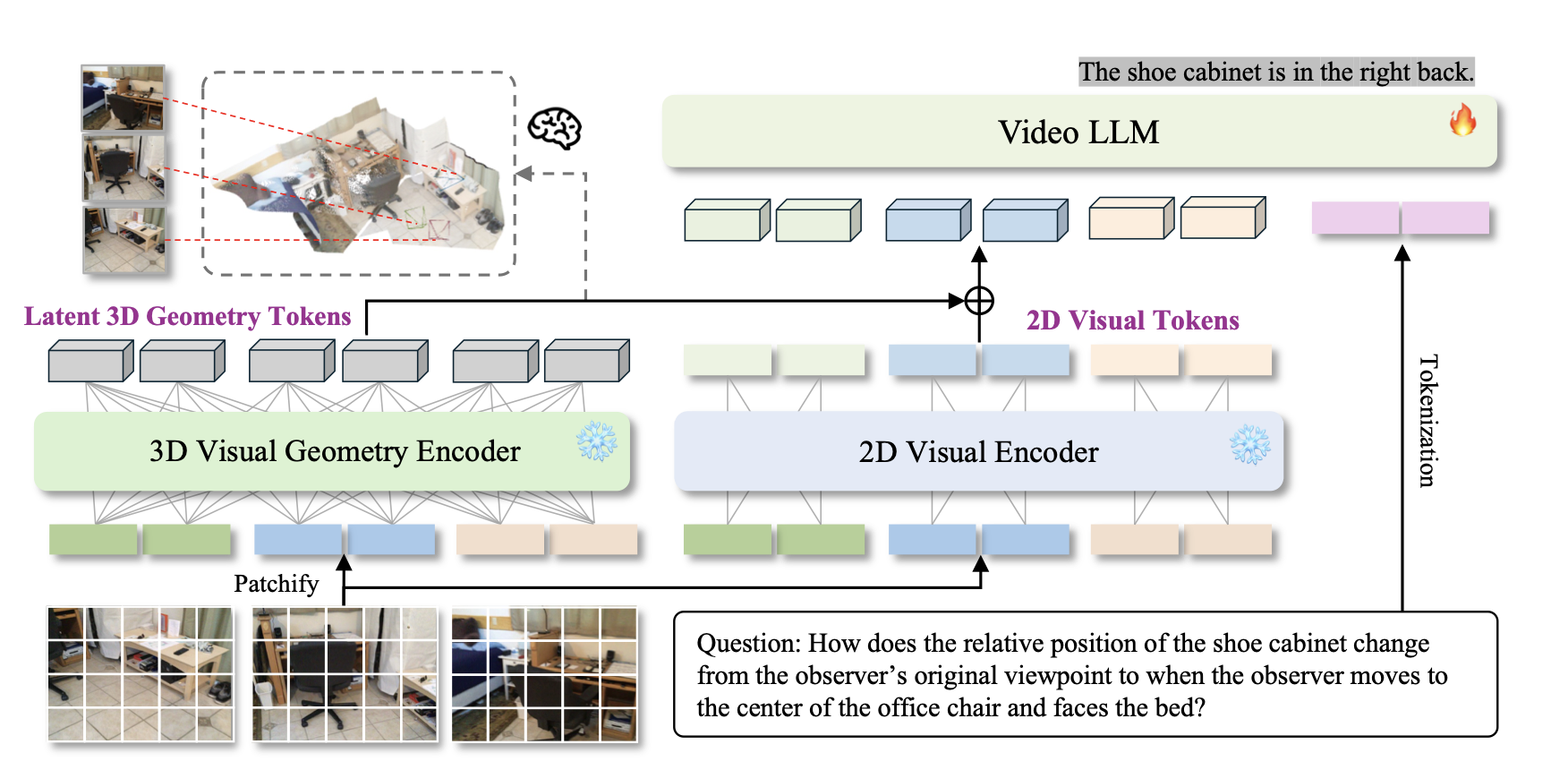
Learning from Videos for 3D World: Enhancing MLLMs with 3D Vision Geometry Priors NeurIPS 2025 Code |
|
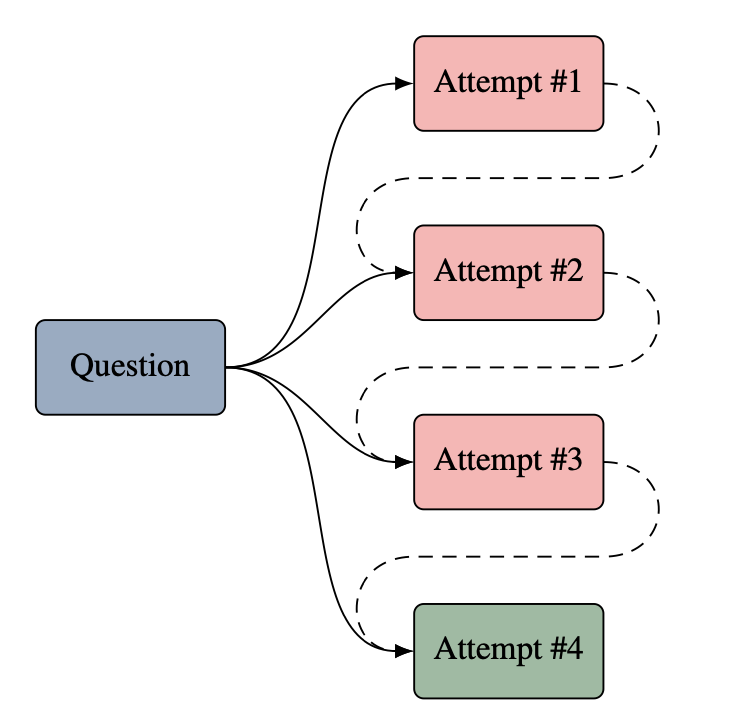
Learning to Reason from Feedback at Test-Time ACL 2025 Code |
|
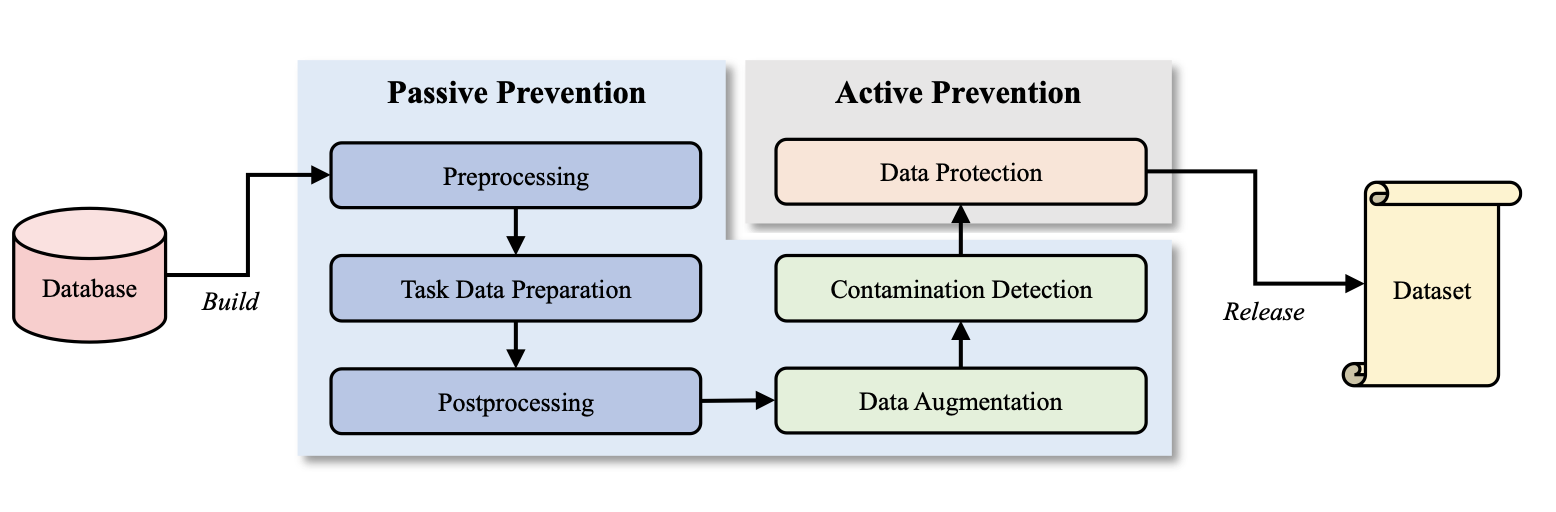
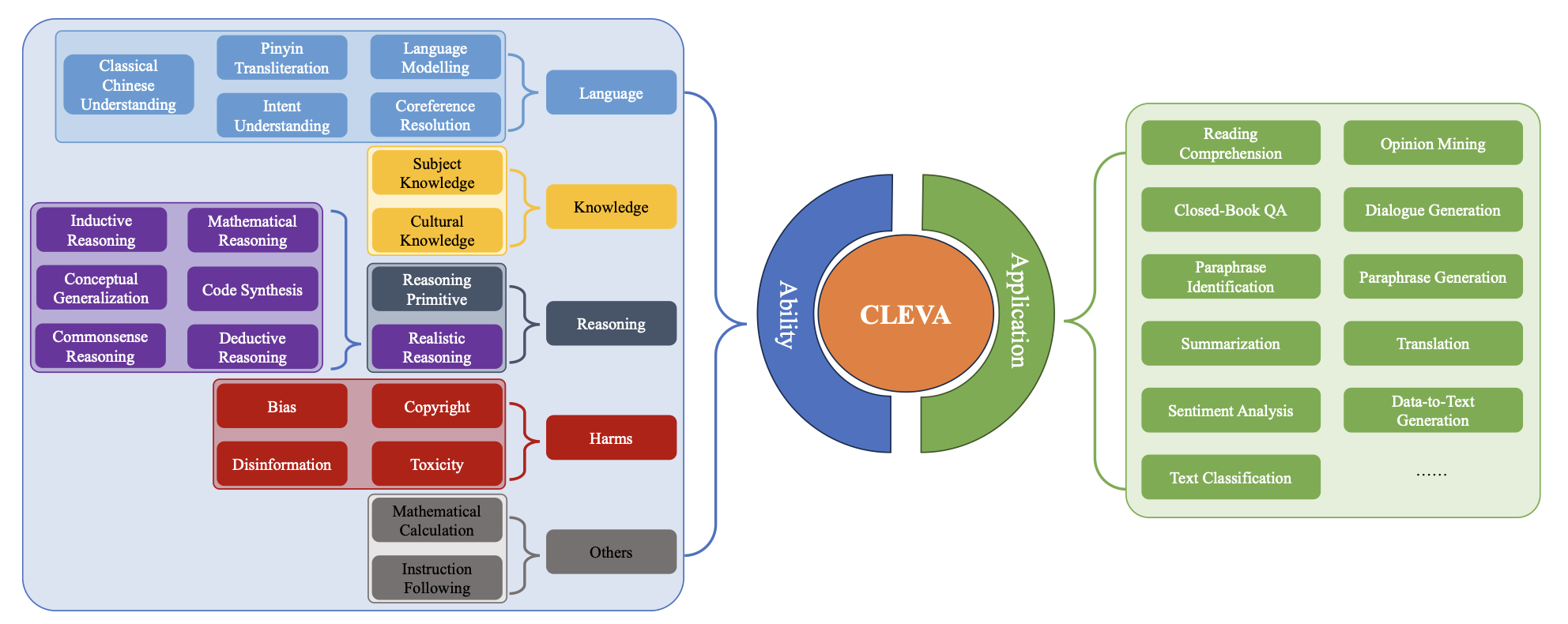
C2LEVA: Toward Comprehensive and Contamination-Free Language Model Evaluation
ACL 2025 Findings Project |
|
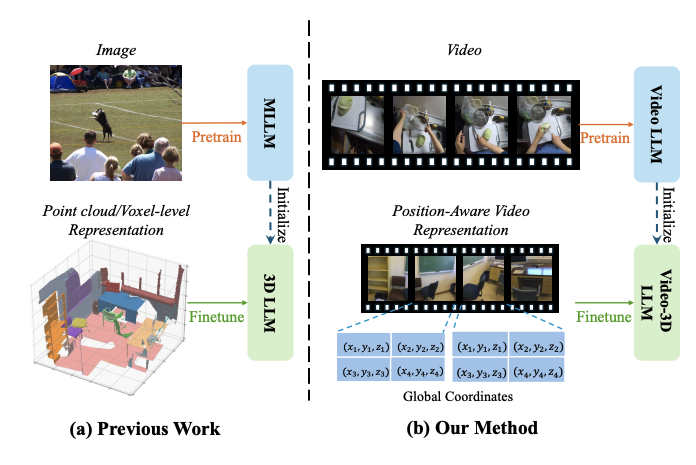
Video-3D LLM: Learning Position-Aware Video Representation for 3D Scene Understanding CVPR 2025 Code |
|
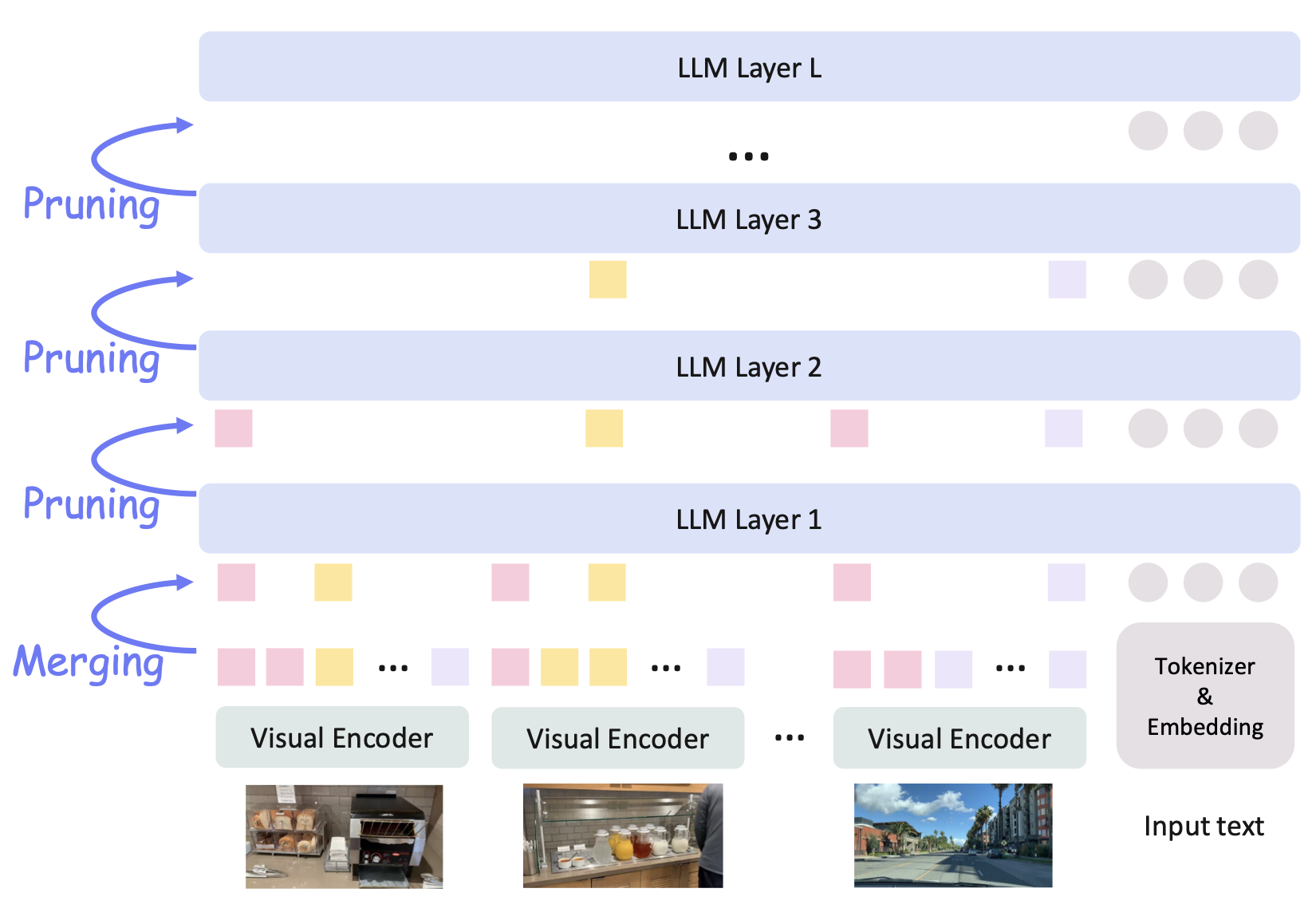
AIM: Adaptive Inference of Multi-Modal LLMs via Token Merging and Pruning ICCV 2025 Code |
|
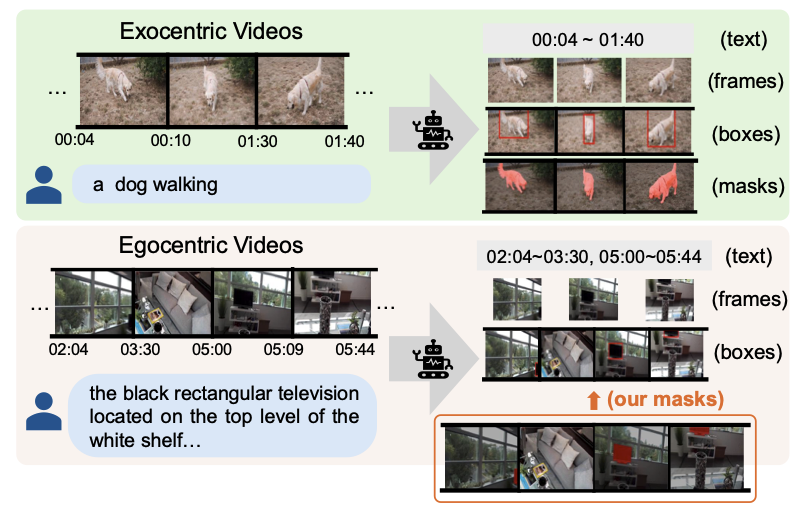
Fine-grained Spatiotemporal Grounding on Egocentric Videos ICCV 2025 Code |
|
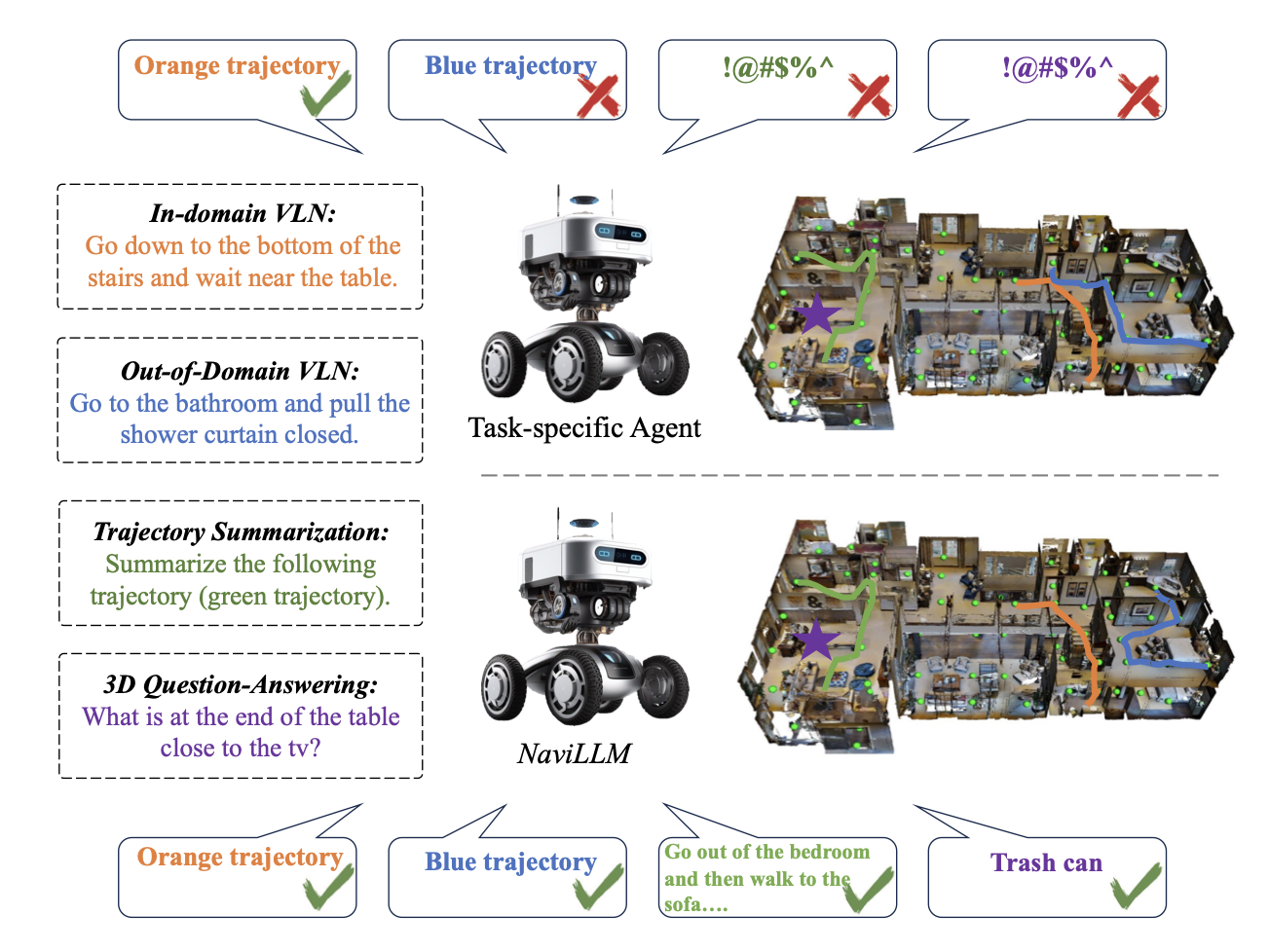
Towards Learning a Generalist Model for Embodied Navigation CVPR 2024 (Poster Highlight) Code |
|
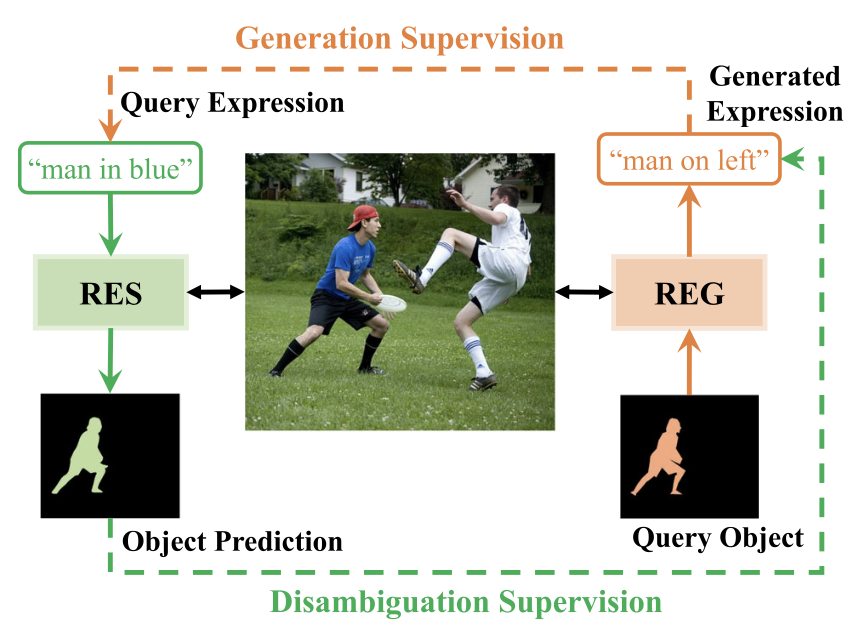
A Mutual Supervision Framework for Referring Expression Segmentation and Generation IJCV 2024 |

|
Making Long-Context Language Models Better Multi-Hop Reasoners ACL 2024 Code |
|
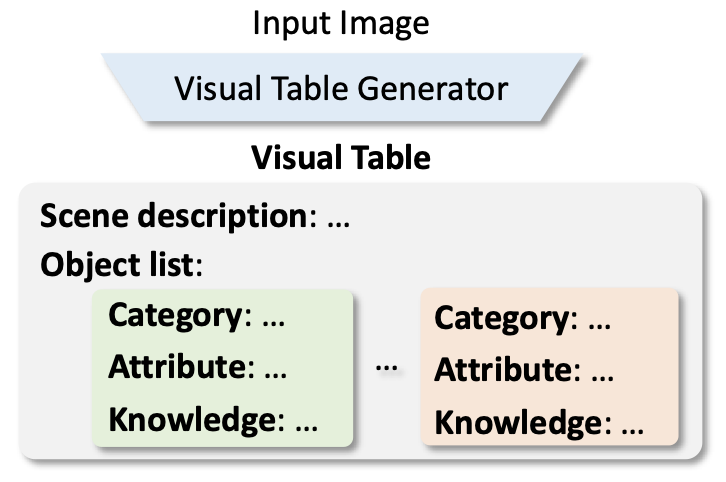
Beyond Embeddings: The Promise of Visual Table in Multi-Modal Models EMNLP 2024 Code |
|
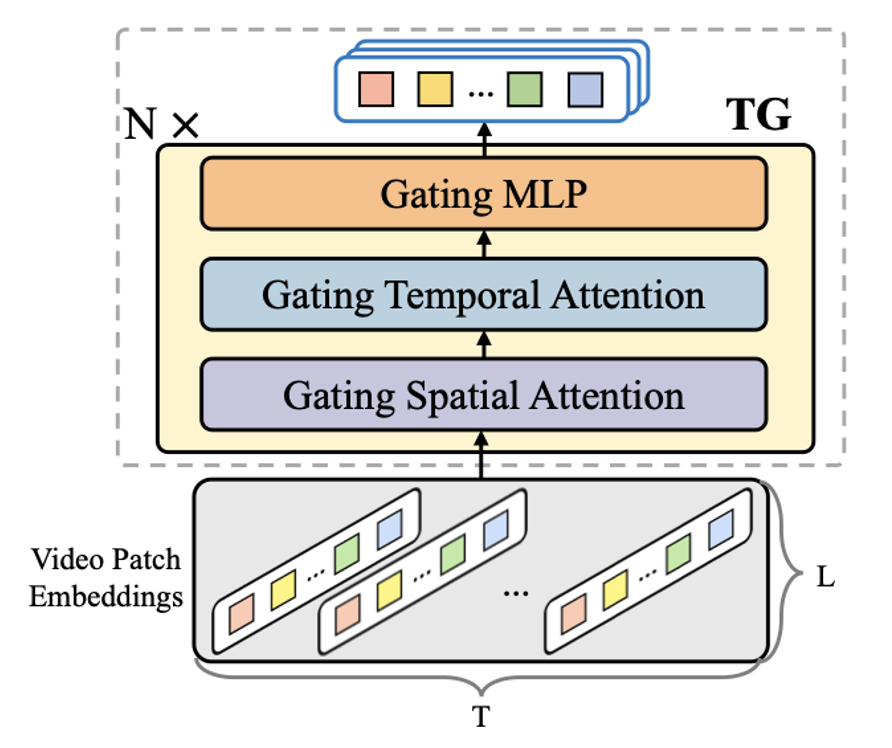
Enhancing Temporal Modeling of Video LLMs via Time Gating EMNLP 2024 Findings Code |

|
Learning Preference Model for LLMs via Automatic Preference Data Generation EMNLP 2023 Long Paper |
|
CLEVA: Chinese Language Models EVAluation Platform EMNLP 2023 System Demonstration Project |
|
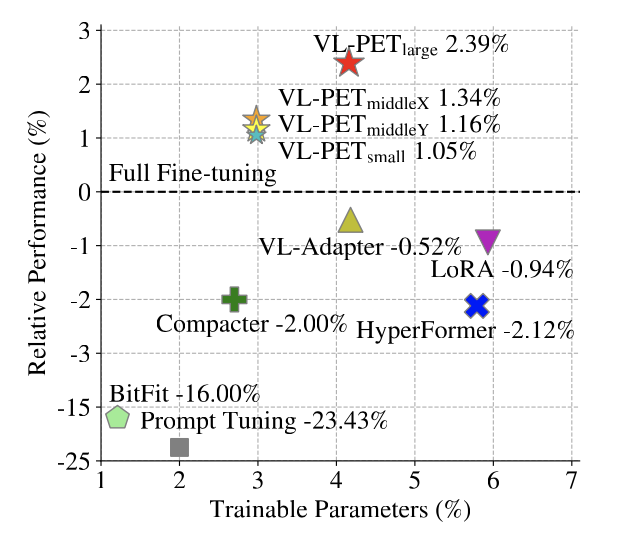
VL-PET: Vision-and-Language Parameter-Efficient Tuning via Granularity Control ICCV, 2023 Code |

|
Multi-View Transformer for 3D Visual Grounding CVPR, 2022 Code |
|
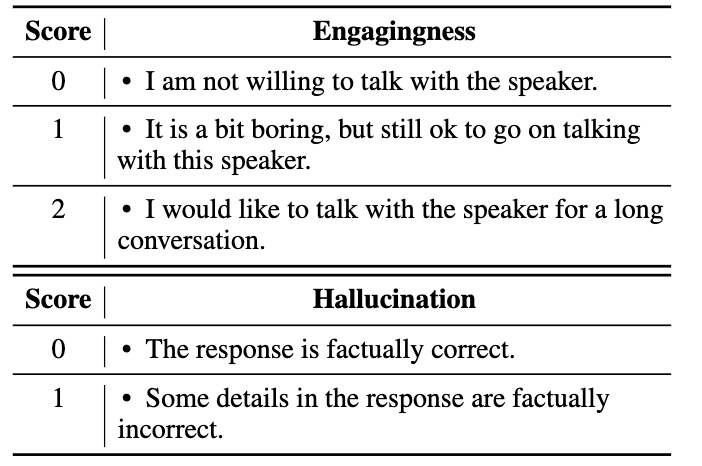
Eliciting Knowledge from Large Pre-Trained Models for Unsupervised Knowledge-Grounded Conversation EMNLP, 2022 Long Paper, Code |
|
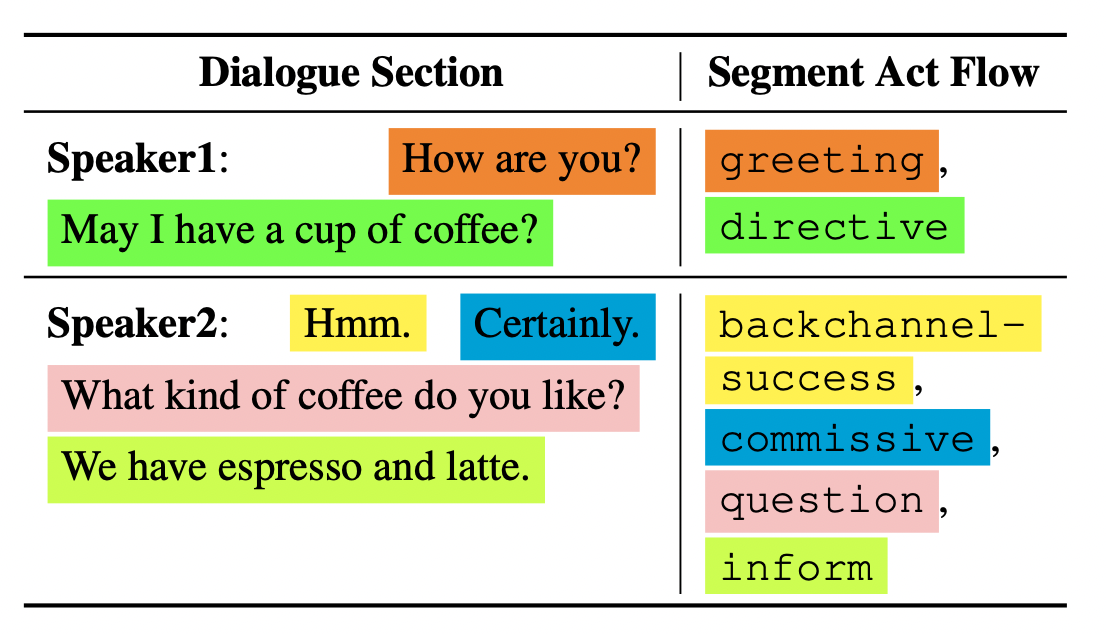
FlowEval: A Consensus-Based Dialogue Evaluation Framework Using Segment Act Flows EMNLP, 2022 Long Paper, Code and Dataset |
|
Probing Structured Pruning on Multilingual Pre-trained Models: Settings, Algorithms, and Efficiency ACL, 2022, long paper |
|
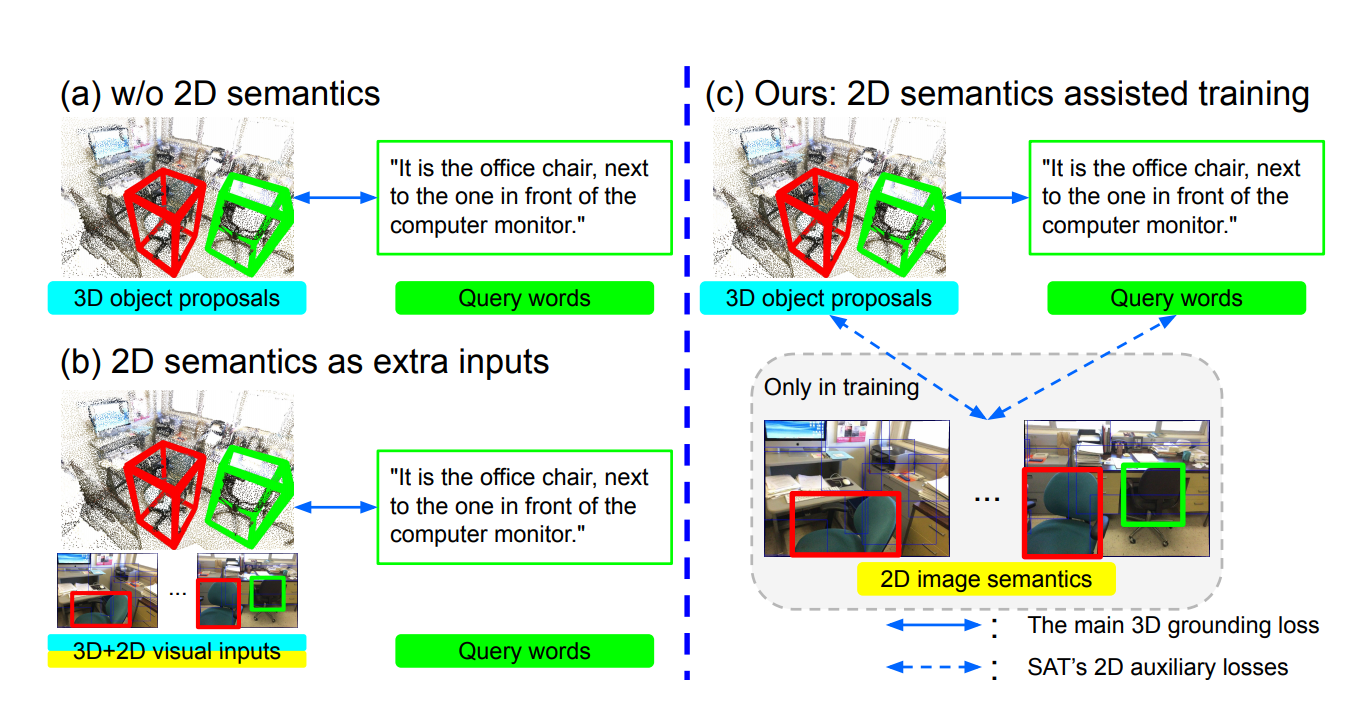
SAT: 2D Semantics Assisted Training for 3D Visual Grounding ICCV, 2021, Oral Presentation Code |
|
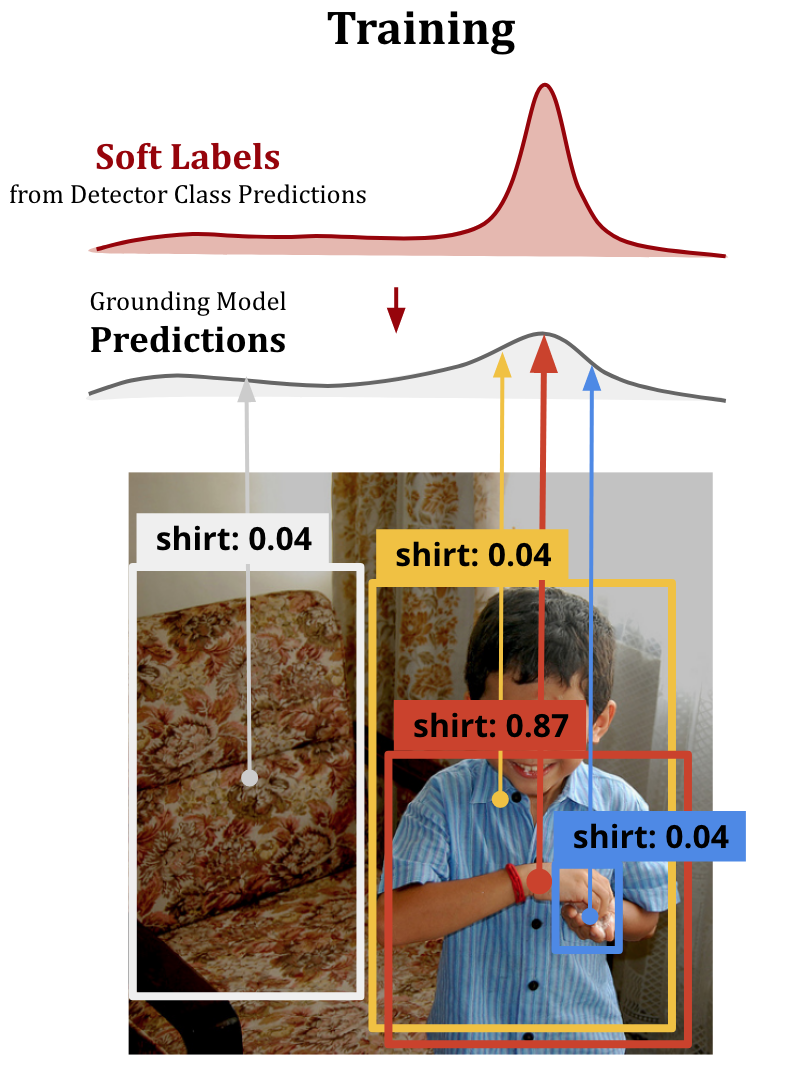
Improving Weakly Supervised Visual Grounding by Contrastive Knowledge Distillation CVPR, 2021 Code |
|
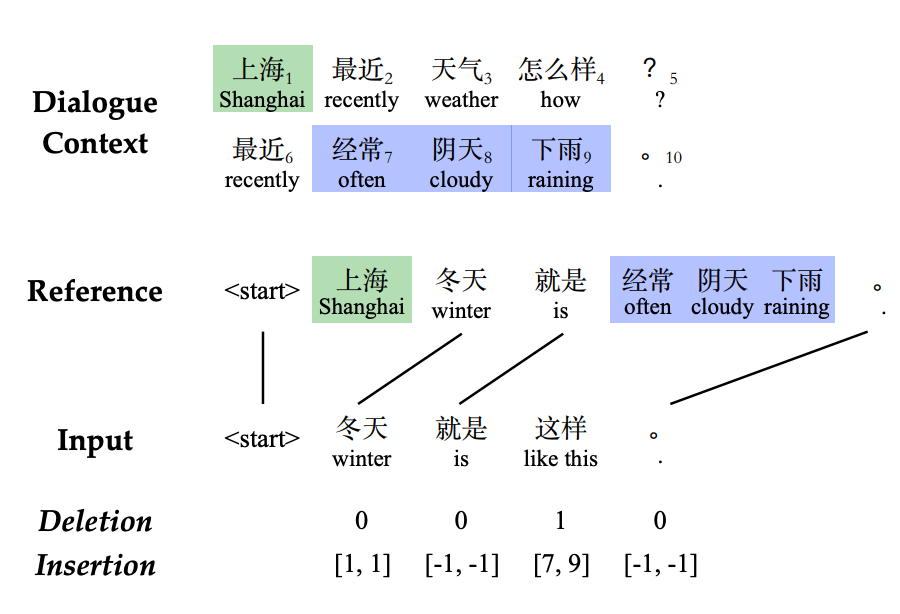
Robust Dialogue Utterance Rewriting as Sequence Tagging EMNLP, 2021, Code |

|
Comprehensive Image Captioning via Scene Graph Decomposition ECCV, 2020 Code |
|
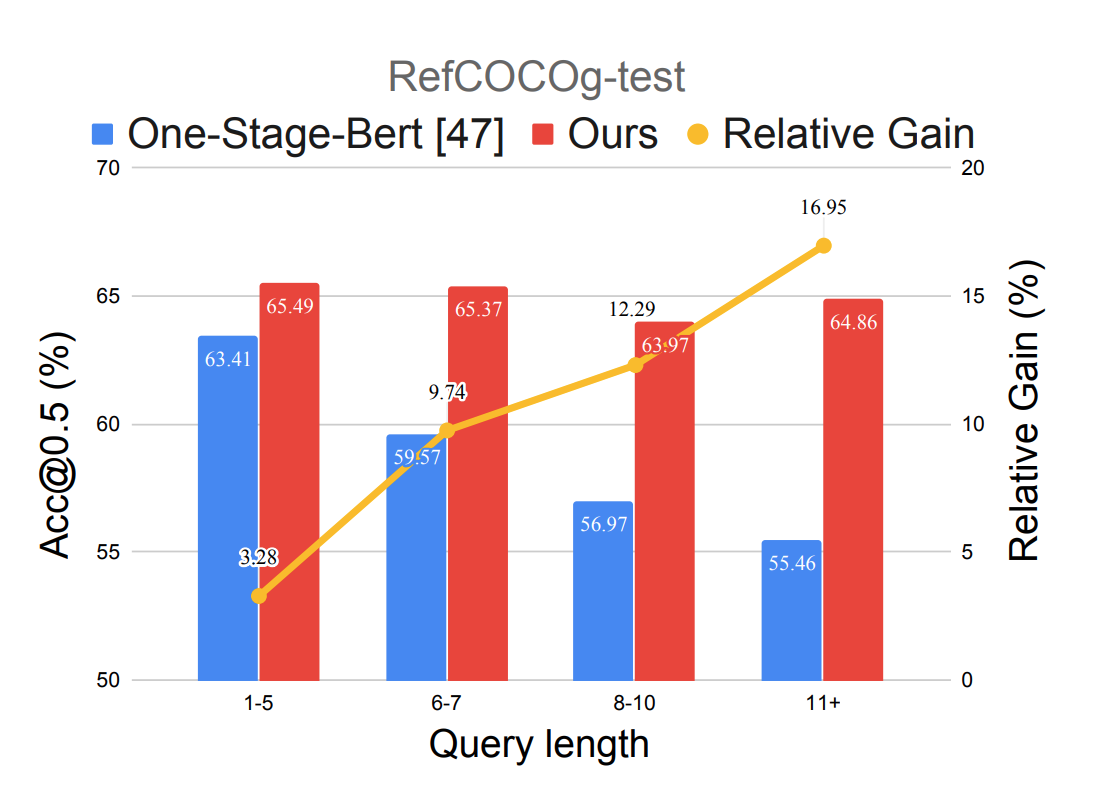
Improving One-stage Visual Grounding by Recursive Sub-query Construction ECCV, 2020 Code |
|
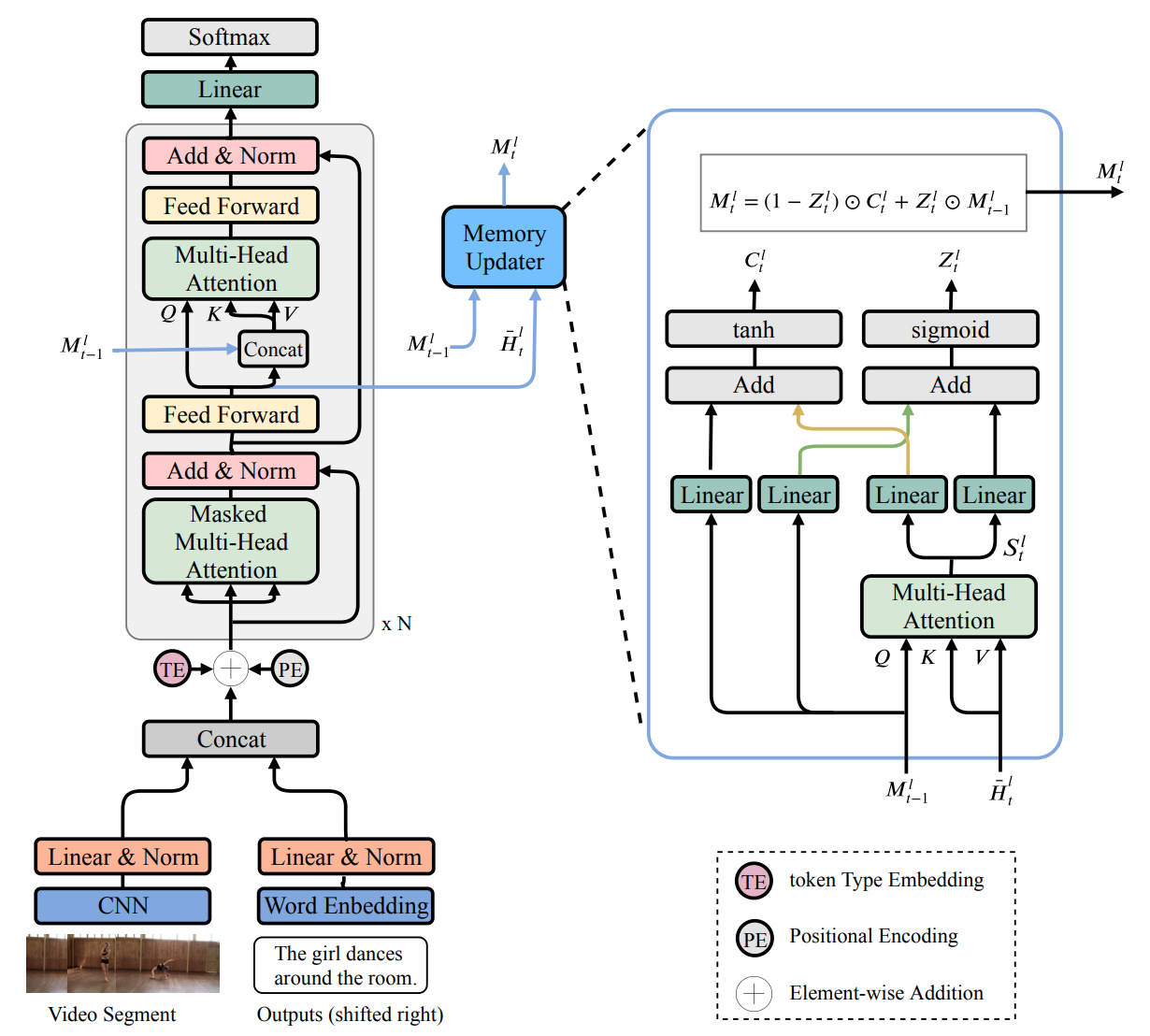
MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning ACL, 2020 Code |
|
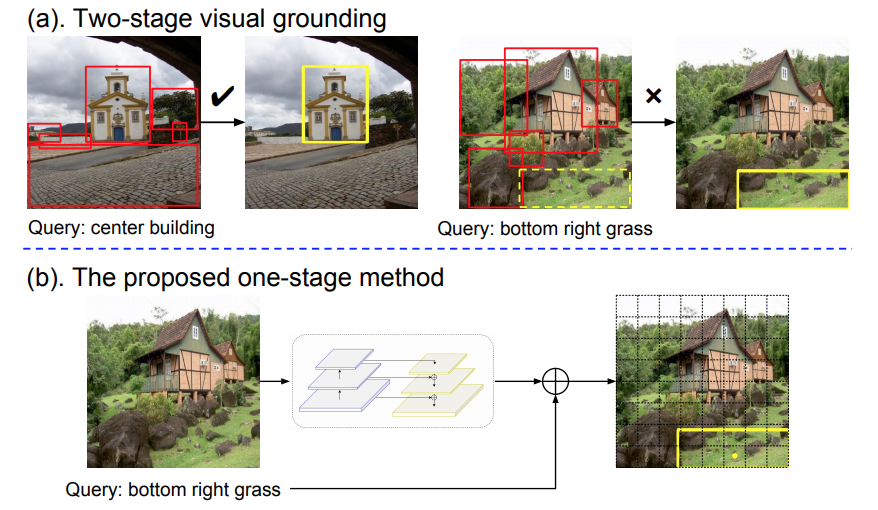
A Fast and Accurate One-Stage Approach to Visual Grounding ICCV, 2019, Oral Presentation Code |
|
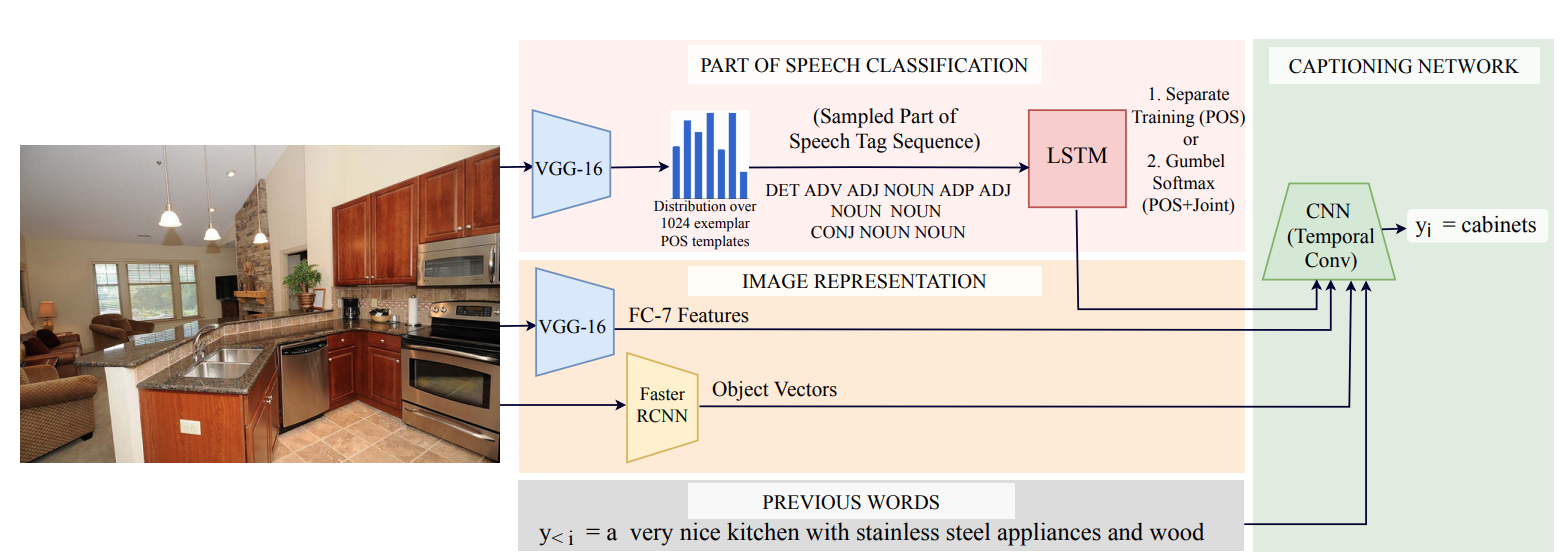
Fast, Diverse and Accurate Image Captioning Guided By Part-of-Speech CVPR, 2019, Oral Presentation |
|
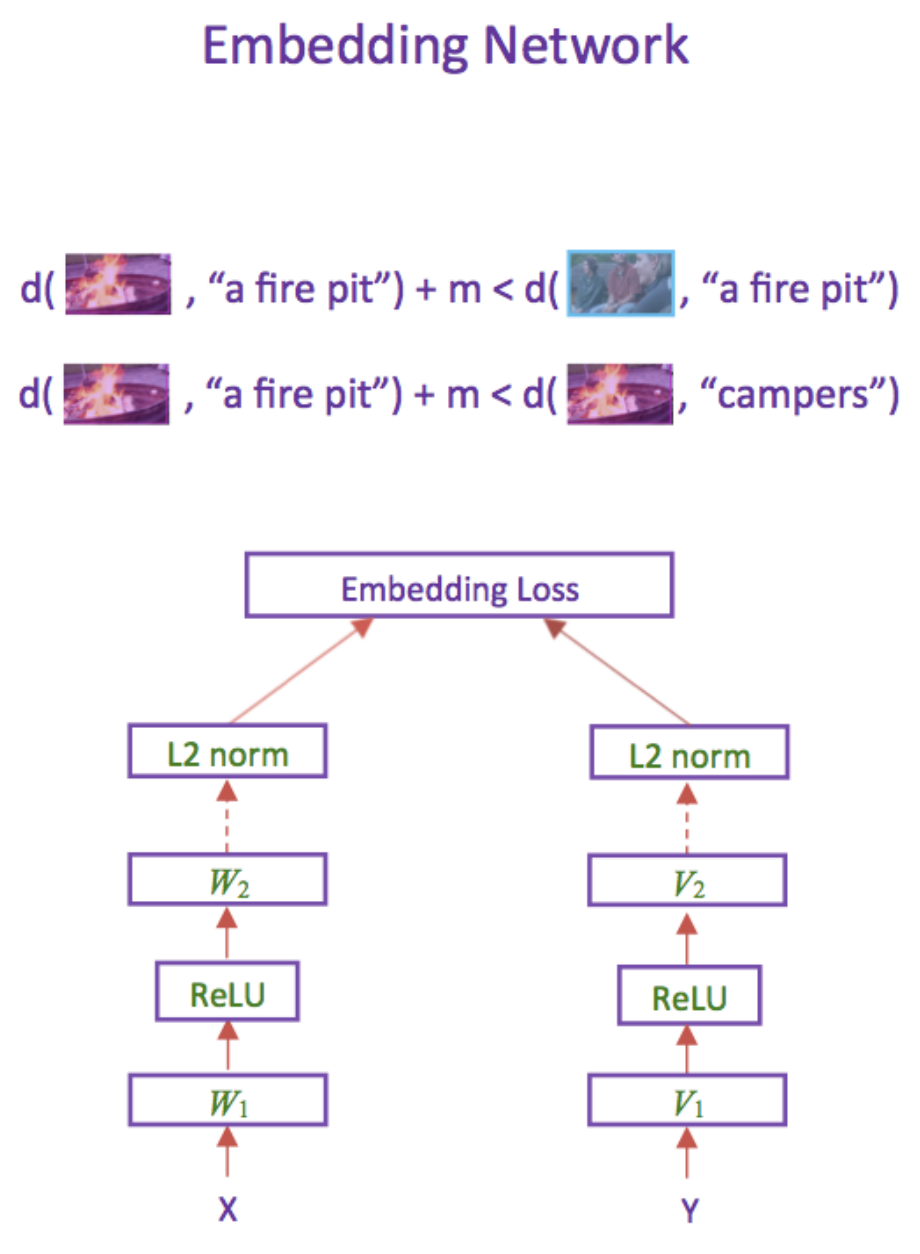
Learning Two-Branch Neural Networks for Image-Text Matching Tasks TPAMI, 2018 Code |
|
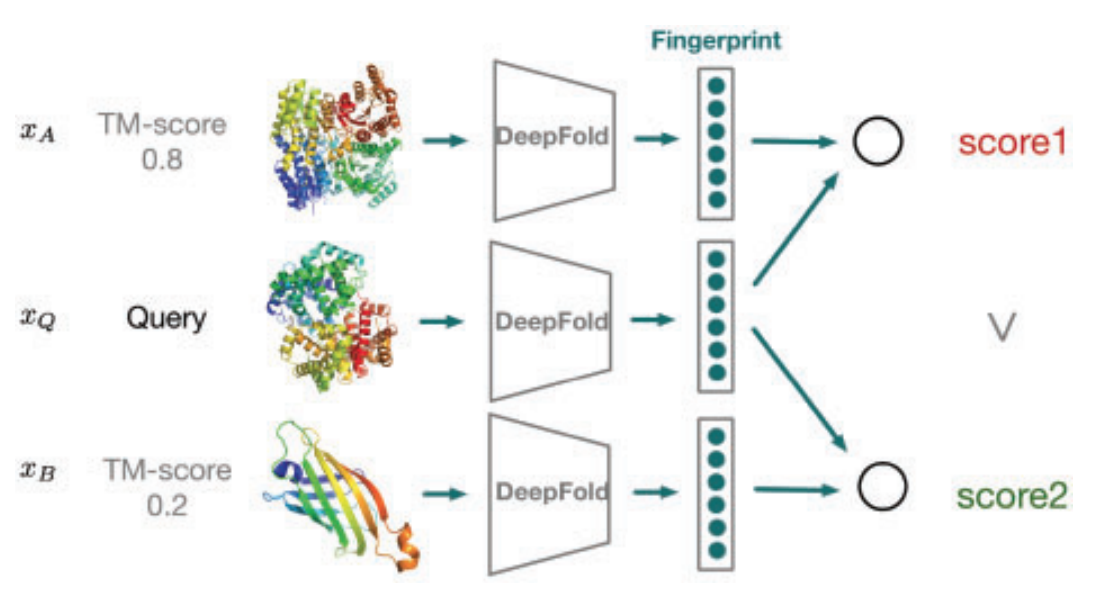
Learning structural motif representations for efficient protein structure search Bioinformatics, 2018 Code |

|
Liwei Wang,
Alex Schwing,
Svetlana Lazebnik NeurIPS, 2017 |

|
Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models IJCV, 2016 Project |

|
Learning Deep Structure-Preserving Image-Text Embeddings CVPR, 2016 Code |
|
|